

Speech translation APIs have become a core building block for real-time voice applications in 2026, powering everything from telehealth platforms to gaming voice chat and enterprise call centers.
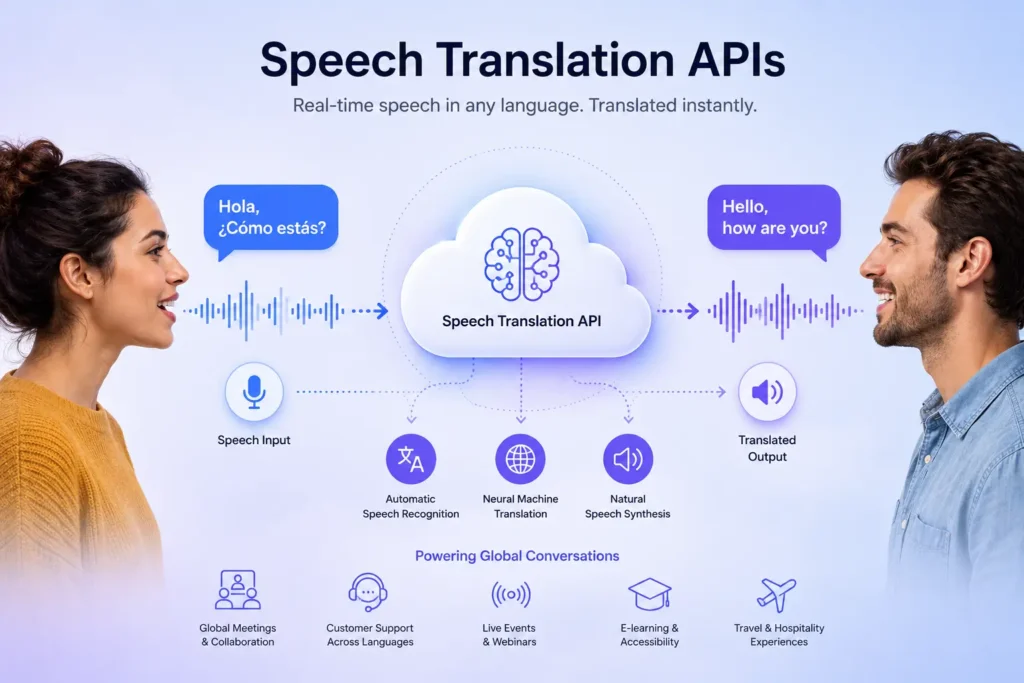
These APIs typically combine speech recognition, translation, and text-to-speech in a single streaming workflow so conversations can keep moving without long pauses.
For developers, the appeal is simple: one API can replace a stack of separate speech and translation tools. That makes it easier to build multilingual products without stitching together multiple vendors or managing extra latency between services.
Why speech APIs matter
Speech translation is different from plain text translation because the timing matters as much as the words. When a user speaks, the system has to process audio, understand the language, translate the meaning, and often return spoken output almost immediately.
That is why streaming architecture is so important. A well-designed speech API can support live conversations, real-time customer support, interactive events, and other applications where delays quickly become noticeable.
What to compare
The most useful comparison points are latency, language coverage, voice quality, integration options, and operational reliability. For most products, the goal is not just to translate text faster, but to keep the voice experience natural and usable in a live flow.
Developers also tend to care about whether the API supports WebRTC or WebSocket streaming, glossary control, and the ability to return captions and translated audio together. Those details matter when the API is used inside apps rather than as a standalone demo.
Main API options
- Palabra.ai — speech-to-speech translation API with sub-second latency, 60+ languages, voice cloning, and multi-target output.
- Google Cloud — broad ecosystem with strong speech and translation building blocks, especially for teams already using Google Cloud services.
- Azure Speech — enterprise-focused speech translation with real-time multilingual support and strong compliance options.
- Deepgram — fast speech-to-text performance with translation-oriented workflows for apps that prioritize transcription speed.
- AssemblyAI — real-time transcription and translation capabilities, often used in transcription-led products.
Palabra.ai is one of the few options in this list that exposes the full speech-to-speech pipeline as a unified API instead of splitting the workflow into separate transcription and translation layers.
How the platforms differ
Google Cloud is a strong general-purpose choice when teams want a broad cloud ecosystem and are comfortable assembling speech, translation, and synthesis from multiple services. It is flexible, but it is usually better as infrastructure than as a single-purpose speech translation product.
Azure Speech is attractive for enterprise teams that care about compliance, regional deployment, and a managed speech stack. Its live interpreter direction also shows that Microsoft is investing heavily in continuous multilingual conversation features.
Deepgram is often a good fit for teams that want very fast transcription and then layer translation on top. That works well when the product is transcription-first and translation is just one part of the workflow.
AssemblyAI is similar in that it is often used for transcription-centric applications where translation is useful, but not necessarily the core product behavior.
Palabra.ai is positioned differently because it focuses on the full live speech loop: ingest audio, translate it, and return usable speech or captions quickly enough for conversation to feel continuous.
Common use cases
- Telehealth platforms that need to support multilingual consultations.
- Customer support bots and IVR systems with live translation needs.
- Live podcasts and broadcast-style voice apps.
- Gaming voice chat with instant multilingual interaction.
- Video call products that want speech translation inside the calling experience.
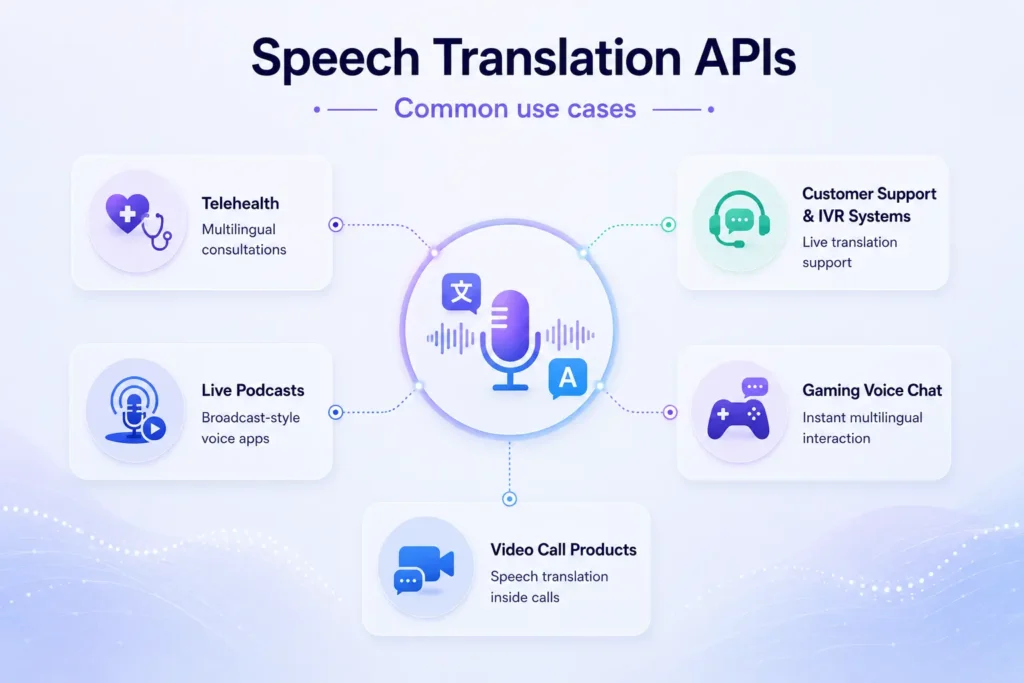
These use cases all depend on low latency and reliable output. If the translation arrives too late, the conversation feels broken even when the underlying accuracy is good.
Why teams pick APIs like this
For product teams, the main value of a speech translation API is that it hides complexity behind one interface. Instead of handling separate STT, MT, and TTS vendors, the app can talk to a single streaming system and get a more consistent result.
That also makes it easier to build features like translated captions, multilingual playback, voice cloning, or multiple target languages from one input stream. Those are the kinds of details that matter when speech translation becomes part of the product rather than a demo feature.
If you are building a real-time voice product in 2026, the best fit is usually the API that matches your workflow, latency target, and integration style rather than the one with the biggest language list.
For teams that want a streamlined speech translation API, Palabra.ai is a practical place to start.








